
プロンプトエンジニアリングとは│カスタマーサポートでの大規模言語モデル必須スキルを紹介
2026/03/26
- AI活用
- 生産性向上




近年、大規模言語モデル(LLM)といったAI技術が急速に発展し、様々な業界でその活用が試みられています。ChatGPTをはじめとする大規模言語モデルは、人間に近い言語能力を操ることが可能で、精度の高い文章生成能力に注目が集まっています。
数ヶ月前までは個人利用にとどまっており、日本では実践的な活用例があまり見られなかった大規模言語モデルですが、ここ最近では日本の企業でも導入事例が増え、成功例が公表されるようになりました。特に企業の適用先として期待されているのがカスタマーサポート領域です。これまでもchatbotや文章要約AIなどが導入されてきたカスタマーサポート領域と大規模言語モデルの愛称は良く、カスタマーサポートのあらゆる業務での適用例が発見されています。
しかし、これらの大規模言語モデルを最大限に活用するためには、「プロンプトエンジニアリング」と呼ばれるスキルが重要になってきます。これは、人間がAIに対して最適な問いを提供する技術で、より精度の高い回答を引き出すための重要な要素です。
本稿では、これからますます重要となるプロンプトエンジニアリングについて詳しく解説します。具体的な技術や実例を通じて、カスタマーサポート業務でどのように活用できるのか、その一端をご紹介いたします。
コンタクトセンター運営課題をお持ちのご担当者様へ
「人材採用がなかなかうまくいかない」「コールセンターの定着率をあげたい」「コールセンターの生産性を高めたい」とお悩みのお客様、まずはお気軽にウィルオブ・ワークにご相談ください。コールセンター専門特化25年、お客様の課題に寄り添った高品質なサービス提供を心がけております。下記より弊社の詳しい情報をご確認いただけます。
大規模言語モデル(LLM)とは
「大規模言語モデル」または「Large Language Model(LLM)」とは、大量のテキストデータを学習することで、自然言語の文脈や構造を理解し、言語処理タスクを解決するためのモデルのことを指します。
まず「言語モデル」とは、ある単語に対して、その次に来る単語の出現確率を訓練データに基づいて予測することができるAIモデルです。例えば、「今日は雨が…」という文が与えられたとき、次に来る単語として「降る」を予測することができます。
言語モデルが「大規模」であるということは、その訓練データが膨大であること、もしくはパラメーター数が膨大であることを指します。これにより、モデルは高い品質と精度、そして多様性を持った文章を生成する能力を獲得することができます。
特に、2020年に公開されたGPT-3は、これまでとは比べ物にならないほど大量のデータを学習した巨大なモデルを使用し、世界中の研究者たちが予想する以上の言語能力を獲得しました。
代表的な大規模言語モデル
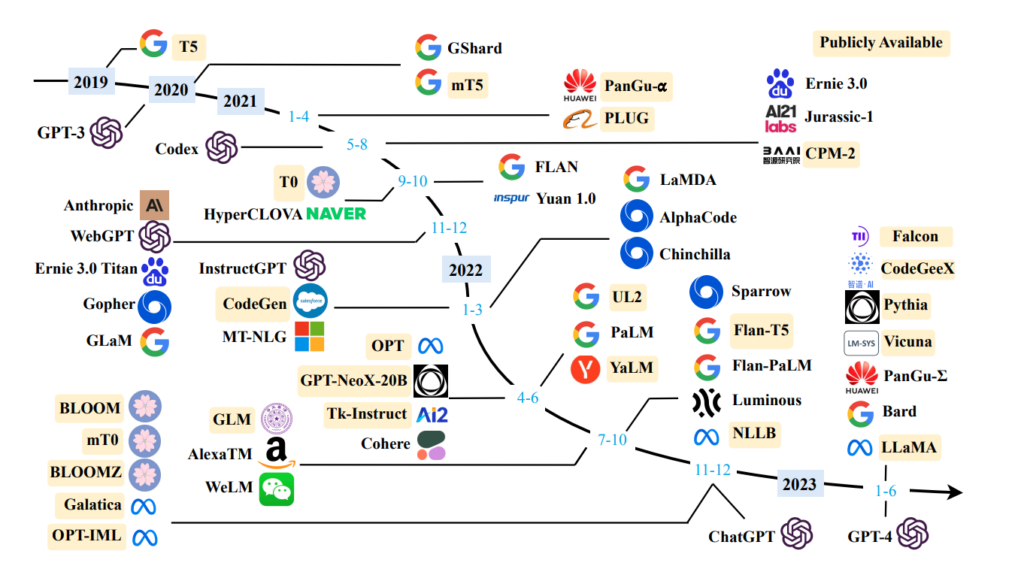
大規模言語モデルは学習させる際に大量の学習資源が必要なため、現状一から作成するためには数億円がかかると言われています。そのため、資金的に体力のあるアメリカや中国の大手企業を中心に研究が進められています。以下に日本でもよく知られている代表的な大規模言語モデルを紹介します。
| 発表年 | モデル名 | 開発元 |
| 2018 | BERT | |
| 2020 | GPT-3 | OpenAI |
| 2020 | ELYZA Brain | ELYZA |
| 2021 | Hyper CLOVA | LINE+NAVER |
| 2023 | GPT-4 | OpenAI |
| 2023 | LLaMA | Meta |
| 2023 | PaLM2 | |
| 2023 | Rinna-3.6B | Rinna |
| 2023 | OpenCALM | サイバーエージェント |
ChatGPTに採用されているGPTシリーズやGoogleのBardに採用されているPaLM2などはサービスとして提供されているため実際に利用されたことがある方も多いかもしません。ChatGPTについては以前の記事も参考にしてください。
また、日本でも日本語に強い大規模言語モデルの開発は進んでおり、早い段階から研究・開発に取り組んでいるELYZAやLINE、2023年に大規模言語モデルの公表をしたRinnaやサイバーエージェントなどがあります。
プロンプトエンジニアリングとは
プロンプトエンジニアリングとは、大規模言語モデルを最大限に活用するための技術のことです。モデルに対する命令(プロンプト)の設計や最適化を行います。
従来の機械学習では、各タスクごとに適切な訓練データを用意し、そのデータを使ってモデルを学習させることで特定のタスクを実現していました。しかし、大規模言語モデルの場合、新しい訓練データを追加することなく、一つのモデルを用いて様々なタスクを実現することが可能です。これは、モデルへの「プロンプト」という指示により、モデルの行動をコントロールするためです。
プロンプトエンジニアリングを理解し適用することで、言語モデルの能力を最大限に引き出し、その限界を理解することができます。大規模言語モデルを実際の業務で活用する際に重要なスキルです。
プロンプトの要素
プロンプトを適切に設計するためには、その構成要素を理解することが不可欠です。プロンプトは複数の要素から成り立ち、それぞれの要素は特定の情報や指示をモデルに伝える役割を果たします。重要なのは、プロンプトの全ての要素が必ずしもすべてのタスクに必要なわけではなく、タスクの特性に応じて使い分けることが求められるという点です。以下に代表的なプロンプトの構成要素を紹介します。
なお、以降の説明は「Prompt Engineering Guide」を参考に、筆者の実験結果をもとにしています。

命令
大規模言語モデルにどのようなタスクを実行させたいかを命令します。命令は例えば「書く」「要約する」「翻訳する」「分類する」「評価する」などです。命令はたいてい冒頭に記載することが望ましいとされており、「#」や「<>」、「###」などの明確な区切り記号を使って、指示と背景情報を分けることが効果的です。
文脈
プロンプトエンジニアリングにおける「文脈」は、モデルがより精度の高い結果を生成する上で重要な役割を果たします。モデルは入力となる文脈に基づいて適切な応答や情報を提供する能力を持っています。したがって、適切な文脈を設定し、その文脈を正確に把握することがプロンプトエンジニアリングで高品質な結果を得るための不可欠な要素となります。
入力データ
プロンプトエンジニアリングにおける「入力データ」は、命令文に補足として必要な情報を示します。AIはこの入力データを利用して文脈を解釈し、それに基づいて適切な応答を生成します。ユーザーが求める結果に近い応答を得るためには、明確で詳細な入力データの提示が重要です。
出力指示
出力指示とは、モデルから得たい出力のフォーマットを指定することです。これは、結果の形状やスタイル、構造を指示します。例えば、出力をリスト形式であることや、表形式のような形であることなどを指定することができます。出力指示を適切に使用することで、必要な情報を正確な形式で取得できます。

プロンプトエンジニアリングのポイント
プロンプトの設計において重要なポイントを紹介します。最近では便利なプロンプトのフォーマットが用意されていますが、ポイントを理解することで、自社用にカスタマイズができたり、狙った結果を引き出すことができます。
繰り返し改善する
一発で最適な結果を得ることは難しく、最初はシンプルなプロンプトから始めて、その結果を見ながら徐々に要素や文脈を追加し、最適化を図ることが重要です。
これは、複雑なタスクをシンプルなサブタスクに分解し、結果が改善されるにつれて徐々に全体を構築していく手法と同じです。この繰り返しのプロセスによって、プロンプトの設計が複雑になりすぎるのを避け、同時に最適な結果を追求することが可能になります。
詳細で具体的に伝える
具体的な指示をすることで、AIモデルは期待する結果をより正確に生成します。たいてい狙った出力が出せない時は、指示に曖昧な部分があるからです。詳細で具体的なプロンプトを設定すればするほど、AIが達成したいタスクを正確に理解し、精度の高い結果を出力する可能性が高まります。
しかし、プロンプトの長さには制限があるため、その範囲内で最大限の情報を伝えることが求められます。全ての詳細を最初から提示する必要はなく、問題解決に必要な具体的な情報のみを選択的に含めることが重要です。これらの詳細は繰り返しの実験と改善により、適切な情報が収束していき、スマートでシャープなプロンプトが完成します。
「しないこと」ではなく「すること」を指示する
「すること」を指示するというポイントは、AIに期待する動作を明示的に定義する上で重要な要素です。「しないこと」を指示すると、AIは逆の行動をすべきであることを適切に解釈することが難しくなります。
例えば、「過度に専門的な用語を使わないで」と指示するよりも、「一般的な用語を使って説明して」と指示した方が、AIにははっきりとした行動指針を提供します。指示は可能な限り具体的で肯定的な形にすることで、AIの性能を最大限に引き出すことができます。
ロールを指示する
プロンプトにどのように振舞ってほしいかを指示することで、精度の高い出力が可能になります。
例えば、「あなたはコールセンターの管理者です」というプロンプトを入力するだけで、コールセンターの領域に寄った出力が可能になります。
プロンプトエンジニアリングのテクニック
プロンプトの研究は日夜進化を続けており、その中でいくつか具体的なテクニックが発見されています。これらのテクニックは、より高度な問題解決や複雑なタスクを達成するために有効な手段です。それぞれのテクニックには特徴があり、目指す目標や適用する状況により適したものを選ぶことで、大規模言語モデルの力をより一層引き出すことができます。
Zero-Shotプロンプティング
「Zero-Shotプロンプティング」は、事前のデモンストレーションや例示なしに、いきなり問いかけを行う手法です。
一般的な知識(モデルに学習されている)文章であれば、Zero-Shotでも高い精度で出力できる可能性があります。しかし、この方法だけでは回答の精度を十分に高められない場合もあります。そのような場合、次に紹介する「Few-Shotプロンプティング」が有効です。
Few-Shotプロンプティング
「Few-Shotプロンプティング」は、モデルに対して具体的な例やデモンストレーションを提供し、それによって質問や指示とその回答のパターンを学習させる手法です。
このプロンプトは、提示したデモがその後の出力に大きな影響を与えます。使い方はシンプルで、プロンプトの中に例示であることがわかるように例文やデモを含めるだけです。より困難なタスクでは、デモを増やすことでより精度の高い出力が可能になります。
注意点として、Few-Shot プロンプティングだけでは複雑な推論問題に対して信頼性の高い回答を得られないことがわかっています。複雑な推論を行う場合は、次に紹介する「Chain-of-Thoughtプロンプティング」によって良い結果が得られます。
Chain-of-Thought(CoT)プロンプティング
「Chain-of-Thought(CoT)プロンプティング」は、連続的な思考を模倣することで、結果の精度を向上させるための手法です。複雑な推論を必要とする問題に対して、この手法を用いると、モデルがステップごとの推論や考え方を学習し、適切に問題を解決します。
この方法では、間違った回答をした場合でも、どの段階でエラーが生じたかを特定することが可能となり、その点も大きな利点となります。
また、発展系として「Zero-shot CoT プロンプティング」というものがあり、これは「ステップバイステップで考えてみましょう」という文言を挿入するだけで連続的な思考が可能になります。
知識生成プロンプティング
「知識生成プロンプティング(Generate Knowledge Prompting)」とは、プロンプトに含まれる情報や知識を強化するための手法です。具体的には、入力文中に特定の知識を組み込むことで、より正確な結果の生成を促します。
これは特に、モデルが答えを出すために必要な情報が不足している場合や、具体的な知識が求められる問題解決などに有効で、その結果として、正しい推論の出力の可能性を高めることができます。
ReAct
「ReActプロンプト」は、「推論(Reasoning)」と「行動(Acting)」を組み合わせた高度なプロンプトエンジニアリング手法です。「推論」と「行動」を組み合わせることで、言語モデルがタスクの推論を行い、具体的な行動を計画します。シンプルな入力プロンプトを使用し、推論後に具体的な行動を列挙することで、より精密な計画を作成し、調整することが可能です。
また、ReActフレームワークは、大規模言語モデルが外部の情報源と対話し、信頼性の高い情報を取得し、回答の品質を高めることも可能にします。

プロンプトエンジニアリングを学ぶ方法
プロンプトエンジニアリングは日々進化する領域で、さまざまなキャッチアップ方法があります。いかにいくつかの学習方法をまとめます。
| 学習方法 | 説明 |
| X(旧:Twitter)で学ぶ |
・X(旧:Twitter)ではリアルタイムに世界中の事例が学べる |
| オンラインで学ぶ |
・すでに体系的にまとめられたドキュメントや講座がある |
| 書籍で学ぶ |
・日本でもChatGPTに関する書籍が多く発売されている |
プロンプトエンジニアリングはまだ発展途上の領域のため、確立された勉強方法があるわけではありません。また、良くも悪くも「大規模言語モデル」がバズワード的に扱われているため、不確かな情報などもネットには多く存在します。回避するためには信頼性の高いソース元から情報を収集しましょう。
プロンプトエンジニアリングを学ぶ注意点
最後に、プロンプトエンジニアリングを学ぶ上での注意点をお伝えします。
まず、プロンプトは万能ではないということを理解する必要があります。それはAIに対する指示や依頼を伝える手段であり、その結果はプロンプトの内容やAIの学習データに大きく影響を受けます。必ずしも期待通りの回答が得られるわけではありませんし、プロンプトエンジニアリングだけでは解決できない問題も多数あります。
また、言語モデルが変わるとエンジニアリングの方法も変わる可能性があります。例えば、GPTシリーズの進化に伴い、以前は必要だったテクニックが新しいモデルでは不要になることもあります。このため、使用するモデルの特性を理解し、適切なプロンプトエンジニアリングを行うことが求められますし、表層のテクニックを使いこなすだけでは、すぐにスキルが陳腐化します。
重要なのはサービスの裏側で動いている言語モデルがどのようなものなのかを理解することと、自分の目的やタスクを具体的に表現できる言語化能力です。
これがあれば、どんなモデルでも上手く使いこなすことができるはずなので、プロンプトエンジニアリングのテクニックを学ぶと同時に、一般的な伝える力や質問力を磨いていくことが大切です。
まとめ
今回は大規模言語モデルを活用するための必須スキル「プロンプトエンジニアリング」について紹介しました。
ChatGPTのようなAIツールは急速に普及していき、今日のエクセルのようにビジネスマンなら誰でも使えるようなツールになっていくと思います。特にカスタマーサポートと大規模言語モデルは相性が良く、それを活用できる人とそうでない人の間には大きな差が生まれるでしょう。
使いこなせるようになるために重要なのは、まずはツールを触ってみることです。実際に業務や活動に活用し、意図した結果が出せるように調整していくことで、ツールの使い方が身につきます。
コンタクトセンター運営課題をお持ちのご担当者様へ
「人材採用がなかなかうまくいかない」「コールセンターの定着率をあげたい」「コールセンターの生産性を高めたい」とお悩みのお客様、まずはお気軽にウィルオブ・ワークにご相談ください。コールセンター専門特化・実績25年以上、実績多数のウィルオブ・ワークが、お客様のコールセンター課題にカスタマイズしたご提案をさせていただきます。ご相談・お見積りは無料!下記ボタンよりお気軽にご相談ください。
Writer編集者情報
-

コネナビ編集部 平井 美穂
2012年、株式会社セントメディア(現:株式会社ウィルオブ・ワーク)へ入社。
コールセンターとオフィスワーク領域に特化した人材サービスに従事し、カスタマーサポートをはじめ、営業やキャリアアドバイザーなど幅広い職務を経験。
現場で培ったCS対応力と人材支援の知見を軸に、採用や運営における課題解決を支援。
2022年からは、コンタクトセンター業界の情報サイト「コネナビ」編集部の責任者として、業界の課題に寄り添う情報発信を推進。
企業向けメディア「コネナビ」と求職者向けメディア「コネワク」を通じて、ユーザーの課題解決と業界の成長に貢献することを目指している。
趣味: 森林浴、神社巡り、アートに触れること
特技: 細かい点に気づくこと

Related article関連記事
関連記事がありません。



