
【最新解説】コールセンターでの生成AI活用|RAG(検索拡張生成)とは?
2025/04/01
- AI活用
- システム導入
- 業務効率化
- 生産性向上




生成AIの活用が急速に進むコールセンター業界ですが、生成AIをフロント業務として活用するには、誤回答のリスクや、最新情報が反映されないといった課題も浮き彫りになっています。そこで今注目されているのが、検索技術と生成AIを融合させた「RAG(検索拡張生成)」という手法です。
この記事では、分かりやすく「RAGとは何か?」という基本概念から、コールセンターでの生成AI活用が抱える課題をRAGがどのように解決するのか、さらには実際の導入手順や成功事例まで徹底解説します。生成AIを本格的に活用し、業務効率化と顧客満足度向上を実現したい方は、ぜひご覧ください。
生成AIに関する過去記事はこちら:
【事例解説】生成AI導入で変わるカスタマーサポート│海外成功事例をご紹介
【2025年最注目】AIエージェントの導入でコールセンターはどう変わる?概要・課題・事例を徹底解説
RAGの基本概念
RAG(Retrieval-Augmented Generation/検索拡張生成)とは、生成AI(大規模言語モデル、LLM)の精度や信頼性を向上させるために生まれた最新のAI技術です。従来の生成AIは、事前に学習した大量の情報をもとに質問への回答を生成しますが、その情報はモデルがトレーニングを終えた時点までに限定され、新しい情報や企業独自のナレッジには対応できない弱点がありました。
RAGは、この課題を解決するために、質問が与えられた際にまず外部のナレッジベースやデータベースなどを検索し、関連性の高い情報を取得します。その情報をもとにAIが回答を生成する仕組みを持っています。そのため、最新の情報や企業内の専門的な知識にも即座に対応できるようになり、回答の信頼性と正確性を劇的に改善できるのです。
一般的な検索エンジンとの違い
通常の検索エンジンは、ユーザーが入力したキーワードに合致した情報を一覧で提供するだけで、その内容の理解や要約はユーザー自身が行う必要があります。一方、RAGは検索結果をもとにAIが自動で内容を理解・要約し、自然な文章で回答を返すため、より迅速かつ効率的に課題を解決できます。
さらにRAGは、回答の出典となる情報を示すことも可能で、回答の信頼性向上にもつながります。「なぜこの回答なのか」「どの情報を元にしているのか」をユーザー自身が確認できるため、特にコンプライアンスが重視される業界や、顧客対応の正確性が求められるコールセンター業務において非常に有用です。
上表のように、RAGは検索と生成AI双方の強みを生かしつつ互いの弱点を補う技術です。
コンタクトセンターへの生成AI活用の課題
生成AIをコンタクトセンター業務に導入する際、多くの企業が抱える課題があります。代表的なものとして、以下のような課題が挙げられます。
正確性の問題(ハルシネーションの発生)
生成AIは非常に流暢で自然な回答を生成しますが、一方で事実に基づかない誤った情報を自信満々に回答する「幻覚(ハルシネーション)」現象が発生するリスクがあります。
生成AIは原理的にハルシネーションを避けられない理由は、その確率的な生成メカニズムにあります。AIは学習したデータパターンに基づいて次の単語や情報を予測する仕組みであり、完全な知識を持たないため情報の欠落を「もっともらしい補完」で埋めようとします。また、言語パターンと事実の区別が内部的に明確でなく、学習データ自体も不完全であるため、真実と創作の境界が曖昧になります。これらの要因が組み合わさり、AIが時に現実に存在しない情報を自信を持って提示する現象が生じるのです。
このような誤回答が顧客の信頼を損なうことになりかねません。特に金融や通信など、正確性が重要視される業界では、この課題は深刻です。
最新情報への対応不足
生成AIモデルは学習した情報に基づいて回答するため、リアルタイムで変化する情報や新しい規定、サービス変更などへの即時対応が困難です。モデルの再訓練や更新には大量の計算資源と時間が必要なため、常に最新の状態に保つことは技術的・経済的に難しいという制約があります。そのため、頻繁に更新があるコールセンター業務では、情報のタイムラグがサービス品質の低下につながります。
また、多くの企業は、製品マニュアルやFAQ、過去の問い合わせ対応事例などの膨大な社内ナレッジを保有しています。生成AIを効果的に活用するためには、これらの社内情報とAIシステムを円滑に連携させる必要がありますが、このナレッジ統合が技術的・運用的に難しく、現場へのスムーズな導入を妨げる要因となっています。
以上のように、生成AIをそのまま活用するだけでは正確性や情報のリアルタイム性や社内ナレッジとの適合性の面で不十分なケースがあります。これら課題を克服するための手段としてRAGが注目されています。
なぜRAGを使えば生成AI活用の課題が解決するか
RAGは、生成AI導入時の課題を克服するための手段として注目されています。どのようにRAGが問題を解決するのかを解説します。
社内知識を反映して正確性向上
RAGは、LLMが回答を生成する際に社内のナレッジベースを参照するため、回答の裏付けがある状態になります。常に根拠のある情報に基づいて生成されるため、誤回答のリスクを著しく低減できます。
また、RAGを使うと、LLMの回答にどの文書を根拠としたかを関連付けることも可能です。ユーザーから見ても回答の出典が確認できるため、「なぜその回答なのか」が透明になり信頼性が向上します。
常に最新情報を提供
RAGを活用することで、モデルのトレーニングを再度行わなくてもナレッジベースの更新だけで最新情報を回答に反映させることが可能になります。単体のLLMでは学習後に登場した新製品や最近の規約変更について対応できない制限がありますが、RAGシステムを導入すれば常に最新状態に保たれるFAQやマニュアルから回答を生成できるようになります。これによりコンタクトセンターでも変化に迅速に対応するサービスの実現が可能となります。
内部データと統合して個別対応を実現
RAGは外部データソースとして顧客プロファイルや過去の問い合わせ履歴を組み込むこともできます。例えば問い合わせ対応時にその顧客の購入履歴を検索し、LLMに与えることで「前回ご購入の商品に関するお問い合わせですね」といった個別の文脈に合った応対が可能です。
以上のように、RAGは生成AIを効果的かつ安全にコンタクトセンター業務に導入するための重要な技術であり、企業の顧客対応力を強化する強力な支援ツールとなります。
コンタクトセンターでのRAGの構築手順
コンタクトセンターにおける一般的なRAGシステムの構築手順を解説します。
参照データの収集とデータベースの構築
まず回答の元となるナレッジデータを洗い出します。FAQ集、製品マニュアル、過去の問い合わせログ、社内Wikiなどが該当します。前提としてこれらのナレッジは最新情報である必要があります。
次に、それらを格納する検索用データベースを選定し、構築していくことが必要になります。すでに、ナレッジシステムが導入されている場合はそれを利用することもできます。
データの前処理とベクトル化
次に、収集した文書データをそのままでは扱えないため、検索しやすい形式に加工します。
具体的には長い文書を短い段落や文のまとまりにするなど、一定の長さで分割(チャンク化)します。分割した各チャンクの内容を「ベクトル埋め込み」という数値の羅列に変換します。これは文章の意味を数百個の数字で表現するもので、コンピュータが文章の類似性を計算できるようにします。
これにより、ユーザーが質問したときに、質問の意味に最も近いチャンクをすばやく見つけることができるようになります。たとえば「返品の方法」という質問に対して、返品に関する情報が含まれたチャンクを正確に検索できるようになります。
検索システム構築
検索システムを作る時には、まず二つの検索方法を組み合わせます。意味を理解する検索(セマンティック検索)と単語そのものを探す検索(キーワード検索)です。
意味を理解する検索は「返品したい」と「商品を戻したい」が同じことだと分かりますが、単語そのものを探す検索は正確な言葉が出てきたときに強みを発揮します。両方を使うことで、より良い検索結果が得られます。
次に、検索結果の順番を決める仕組みを作ります。これは「この回答はどれくらい質問に関係があるか」を計算する方法です。質問の意味との近さ、キーワードがどれだけ含まれているか、情報の新しさなどを考慮して、最も役立ちそうな情報を一番上に表示します。
また、ユーザーが入力した質問も整えます。「パソコン」と「PC」のような言葉の違いを統一したり、質問に関連する言葉を追加したり、曖昧な質問をより明確にしたりします。これによって、ユーザーが何を知りたいのかをシステムがより正確に理解できるようになります。
生成システム構築
生成システムを構築する際には、まず検索で見つけた情報を大規模言語モデル(LLM)に伝える方法を工夫します。これが「プロンプトエンジニアリング」です。例えば「以下の情報に基づいて回答してください」という指示と検索結果を組み合わせ、さらに「簡潔に説明する」「専門用語を避ける」などの細かい指示を加えます。こうすることで、検索結果を適切に活用した回答が得られます。
次に、システムから返ってくる回答の形式を統一します。たとえば、最初に結論を述べてから詳細を説明する、参考情報の出典を必ず示す、専門用語には説明を付けるなど、一定のルールを設けます。これにより、ユーザーは回答の構造を予測しやすくなり、必要な情報をすぐに見つけられるようになります。
最後に、どの言語モデルを使うかを決め、システムに組み込みます。用途や予算、セキュリティ要件などを考慮して最適なモデルを選び、APIを通じてシステムと連携させます。これらの要素がうまく機能することで、検索で得た情報をもとに、的確で一貫性のある回答を生成できるシステムが完成します。
システム全体のテストと調整
システムの品質を確認するために、まず検索機能がどれだけ正確に情報を見つけられるかを評価します。「適合率」は検索結果の中で実際に関連ある情報の割合を、「再現率」は関連情報のうちどれだけを見つけられたかを示します。また、システムが生成した回答が正しいかどうかをセンターの品質担当などが確認し、誤った情報や曖昧な説明がないかをチェックします。
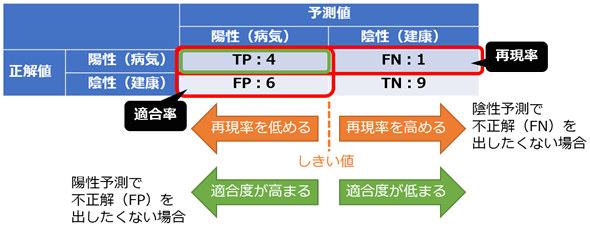
次に、システムの動作速度や処理能力を測定します。ユーザーが質問してから回答が返ってくるまでの時間(レイテンシ)や、同時にどれだけの問い合わせを処理できるか(スループット)を調べます。特にコンタクトセンターでは多くの問い合わせを同時に処理する必要があるため、この点は重要です。遅すぎたり処理能力が足りなかったりすると、顧客を待たせることになります。
これらの評価を通じて、システムの弱点や改善点を特定し、本格的に導入する前に必要な調整を行うことができます。技術的な性能だけでなく、実際の利用者にとって役立つシステムになっているかを確認することが大切です。
運用と継続改善
システムを長期間にわたって効果的に運用するためには、まず情報の鮮度を保つ仕組みが必要です。製品情報やサービス内容は常に変化するため、定期的にナレッジベースを更新する手順を確立します。例えば、毎月の定例作業として新しい情報を追加したり、古くなった情報を修正したりする担当者や手順を決めておきます。また、更新された情報を自動的に取り込む仕組みを作れば、人の手間を減らすこともできます。こうして常に最新の正確な情報をもとに回答できるようになります。
次に、システムの変更履歴を管理する体制を整えます。AIモデルやプログラムを改良するたびに、どんな変更をしたのか、なぜその変更が必要だったのか、どのような効果があったのかを記録します。問題が発生した場合に以前のバージョンに戻せるようにしておくことも重要です。こうした管理があれば、システムの進化の過程を追跡でき、トラブル発生時にも原因特定や復旧が迅速に行えます。
最後に、情報の安全を守る対策を講じます。顧客との会話には個人情報が含まれることが多いため、適切な保護が不可欠です。データの暗号化、アクセス権限の設定、定期的なセキュリティ監査などを実施します。また、利用ログを記録して不審なアクセスがないか監視したり、AIが取り扱ってはいけない情報の種類を明確にしたりすることも大切です。これにより顧客の信頼を保ちながらシステムを運用できます。
RAG構築はこのように、従来のAIプロジェクトで必要とされてきたプロセスに近い対応が必要になります。最近では、自社で一から開発しなくても、クラウドサービスの機能を利用することで比較的短期間(数ヶ月程度)での導入も可能になっています。
RAG構築の課題・注意点
RAGを導入・構築する際には、その運用上の課題や注意点についても把握しておく必要があります。以下に主なポイントをまとめます。
知識データの精査と管理
RAGの出力品質は組み込むナレッジベースの質に大きく依存します。古いマニュアルや誤情報が含まれていれば誤った回答の原因になります。したがって導入時には社内ナレッジの棚卸しと精査が重要です。
また、運用中も定期的な情報更新が不可欠で、問い合わせ頻度の高い質問に関するデータを充実させるなどナレッジ管理の体制整備が求められます。
検索精度と応答品質のチューニング
ベクトル検索を用いるRAGでは、適切な文書が検索されるように調整することが重要です。意図した回答にならない場合、関連する文書が拾えていない可能性があります。
また、LLMへのプロンプト設計も応答品質に影響します。「この情報に基づき簡潔に答えて」など指示を工夫しないと、余計な創作をしてしまうこともあります。これらは開発・検証段階での綿密なチューニングと、リリース後の改善によって最適化していく必要があります。
UXを実現するための性能
特に顧客とのリアルタイムでのやりとりに、RAGを導入する際は応答速度も重要で、検索+生成の処理が遅すぎるとユーザー満足度を下げてしまいます。そのため、高速なベクトルDBの採用や、レスポンス時間を抑える工夫(例えば検索結果を必要最小限に絞る、LLMの出力長を制限する等)など、実運用でストレスのない応答速度を出すチューニングが必要です。
セキュリティとプライバシー
RAGでは社内の機密データや個人情報がLLMの入力や出力に含まれる可能性があります。そのためデータ取り扱いには細心の注意が必要です。クラウドのLLMサービスを使う場合、機密情報を直接クラウドに送信しないような対策も必要になることがあります。
また、RAGを通じてLLMが社内の秘密情報を生成出力してしまうリスク(例えば未公表の製品情報を回答してしまう等)もゼロではないため、プロンプトで出力制限をかける、社内機密データはナレッジベースに含めないなどの対策が必要です。
コンタクトセンターにおけるRAG活用の成功事例
最後に、実際にコンタクトセンター業務でRAGや生成AIを活用している事例を紹介します。国内の先行事例を中心に、効果や取り組み内容を見てみましょう。
三井住友カード
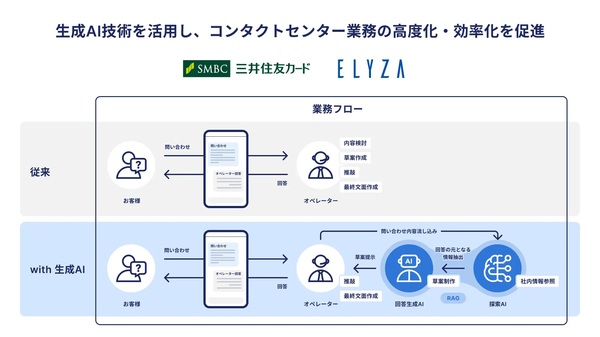
三井住友カードは、コンタクトセンターにおいて問い合わせへの回答草案を自動生成するAIシステムを構築し、2024年6月末からメール回答業務での本番運用を開始しています。
このシステムはELYZAの支援のもと、RAG構成を採用して社内データを検索し回答草案を生成しています。月間約50万件を超える問い合わせに対応するため、対応品質と対応可能件数の向上が急務となっていたことから導入に至りました。
2024年内にはチャット対応にも適用予定で、最終的には顧客問い合わせ対応時間を最大60%程度短縮する見込みです。
DoorDash(米国の事例)
DoorDashは毎日、消費者、販売者、およびプラットフォームを通じて配送する独立請負業者である Dasher から、コンタクトセンターを通じて数十万件のサポートリクエストを受けています。Dasher ドライバーは、車を運転して販売者や消費者を訪問するため、問い合わせる場合には、チャットするよりも、サポートに電話することを好む傾向がありました。
そこで、同社では効率化のために生成AIを活用したセルフサービスを強化するため、AWSの生成AIイノベーションセンタープログラムと連携し、わずか2ヶ月で音声操作可能な生成AIコンタクトセンターソリューションを構築しています。検索拡張生成(RAG)を活用してナレッジベースを拡充し、応答レイテンシーを2.5秒以下に抑え、Dasherドライバーに迅速かつ正確な回答を提供しています。
その結果、エージェントへの転送が減少し、初回解決率が向上して運用コストも削減されました。現在はさらに機能を追加し、質疑応答だけでなくユーザーに代わってアクションを実行できるよう拡張を進めています。
まとめ
本記事では、コンタクトセンターの生成AI活用の鍵となるRAGについて解説しました。
コンタクトセンター業務にRAG(検索拡張生成)を取り入れることは、顧客対応の精度向上と効率化を両立させる重要な意義があります。生成AIによって柔軟な応対が可能になりましたが、正確性や社内適合性の課題もあり、RAGはその解決策として社内ナレッジをAIで即座に活用する架け橋となっています。
今後は生成AIとRAGの組み合わせがコンタクトセンターの標準アーキテクチャになる可能性があり、業界や企業規模を問わず適用が広がれば問い合わせ対応の在り方が根本的に変革されるでしょう。AIと人間が協働するコンタクトセンターという方向性は確実に進んでおり、RAGを含む生成AI技術を取り入れることで顧客体験向上と運営効率最大化の両立が可能になります。
コスト削減や業務効率化に課題を感じている方へ…
コスト削減や業務効率化には様々な手段がありますが、「どの手段が自社に合っているのかわからない」とお困りではありませんか?システム導入やBPOなど、豊富なサービス支援実績のあるウィルオブが、貴社の課題に最適な解決策を提案いたします。ぜひ、下記のリンクより弊社のサービスをご覧ください。
Writer編集者情報
-

コネナビ編集部 平井 美穂
2012年、株式会社セントメディア(現:株式会社ウィルオブ・ワーク)へ入社。
コールセンターとオフィスワーク領域に特化した人材サービスに従事し、カスタマーサポートをはじめ、営業やキャリアアドバイザーなど幅広い職務を経験。
現場で培ったCS対応力と人材支援の知見を軸に、採用や運営における課題解決を支援。
2022年からは、コンタクトセンター業界の情報サイト「コネナビ」編集部の責任者として、業界の課題に寄り添う情報発信を推進。
企業向けメディア「コネナビ」と求職者向けメディア「コネワク」を通じて、ユーザーの課題解決と業界の成長に貢献することを目指している。
趣味: 森林浴、神社巡り、アートに触れること
特技: 細かい点に気づくこと

Related article関連記事
関連記事がありません。




