
コンタクトセンターの生成AIで起きる「ハルシネーション」とは?現場で効く3つの対策と設計の勘所
2026/02/03
- AI活用




コンタクトセンターにおける生成AIの導入が急速に進んでいます。国内企業の約半数がすでに実務で運用を開始しており、その多くが応対内容の要約やオペレーターの回答支援で成果を上げています。
しかし、導入の障壁として常に議論されるのが、AIが事実に基づかない情報を生成する「ハルシネーション」のリスクです。誤回答が一度発生すれば、顧客体験の低下だけでなく、法務リスクやブランド毀損(きそん)に直結しかねません。
本記事では、フロント対応に焦点を当て、ハルシネーションに対する具体的な対策と設計のステップを解説します。
ハルシネーションとは?コンタクトセンター文脈での定義
生成AIにおけるハルシネーションとは、AIが学習データのパターンに基づき、あたかも真実であるかのように誤った情報を出力する現象を指します。
コンタクトセンターにおけるハルシネーションの例
コンタクトセンターでは、事実の捏造、文脈の混同、不適切なアドバイスといった形で顕在化します。
事実の捏造としては、「このプランには無料で海外旅行保険が付帯しています」といった、実在しない特典や規約の案内が挙げられます。
文脈の混同では、過去の問い合わせ内容や無関係なマニュアルを引用して回答するケースがあります。
また、不適切なアドバイスとして、専門家の判断が必要な領域(医療、法的アドバイスなど)で、AIが勝手に判断を下すことがあります。
なぜハルシネーションは起こるのか(原因の全体像)
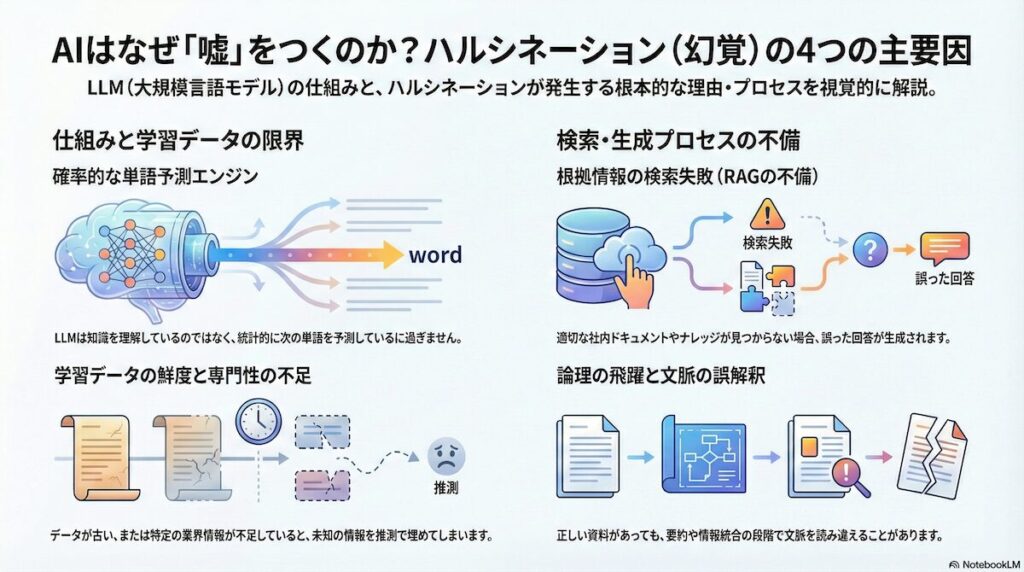
根本的な原因は、LLMが辞書や百科事典のような「知識ベース」ではなく、大量のテキストデータから学習したパターンに基づいて次の単語を予測する「確率的な単語予測エンジン」であることにあります。
第一に、学習データの限界が挙げられます。LLMの学習に使用されたデータが古い場合、最新の製品仕様や料金プランについて正確な情報を持っていません。また、特定の業界や企業固有の情報が学習データに不足している場合、AIは未知の情報を文脈から推測して埋めようとするため、もっともらしいが誤った回答を生成してしまいます。
第二に、検索フェーズの失敗があります。RAG(Retrieval-Augmented Generation)と呼ばれる仕組みでは、回答の根拠となる社内ドキュメントやナレッジベースを検索してから回答を生成しますが、この検索段階で適切な情報を見つけられないことがあります。
第三に、生成プロセスの欠陥が存在します。検索で正しい資料を取得できたとしても、その情報を要約したり複数の情報を組み合わせて回答を構成する段階で、論理が飛躍したり、文脈を誤解釈したりすることがあります。
コンタクトセンターでハルシネーションが問題になる理由
コンタクトセンターという場所は、企業にとって顧客との信頼関係を構築する最後の砦であり、同時に法的なコンプライアンスを厳守すべき窓口でもあります。
一般的な事務作業におけるAIの誤字脱字程度であれば修正で済みますが、コンタクトセンターにおける情報の誤りは、即座に企業の責任問題へと発展します。そのため、他部署以上にハルシネーションに対する感受性が高く、慎重な対応が求められるのです。
現場へのインパクト
ひとたびハルシネーションが発生し、誤った情報が顧客に届いてしまうと、その影響は連鎖的に広がります。まず現場レベルでは、誤案内の訂正とお詫びのために通常以上の二次対応コストが発生し、応対品質管理部門はその原因究明と再発防止策の策定に膨大な時間を取られることになります。
より深刻なのは、顧客の不信感によるブランド毀損(きそん)です。現代の顧客はソーシャルメディアを通じて不満を瞬時に拡散する力を持っており、AIによる不誠実な対応やデタラメな回答は、企業のデジタル戦略全体への疑念を抱かせるきっかけになりかねません。
加えて、金融や保険、医療といった規制の厳しい業界では、重要事項の説明漏れや不実告知が行政処分の対象となるリスクも含んでおり、一つの誤回答が経営の根幹を揺るがす可能性すら秘めているのです。
特に危険な領域
AIに完全に任せるのが危険であり、現時点では人間による監視や特定のテンプレート回答が必要な領域を明確にする必要があります。
具体的には、契約の締結や解約、返金条件に関する案内は、金銭的なトラブルに直結するため非常に高いリスクを伴います。また、副作用の可能性を伴う医療行為のアドバイスや、特定の金融商品への投資推奨などは、専門の免許や資格を持つ人間以外の回答を認めるべきではありません。
個人情報の取り扱いに関する説明や、法的義務を伴う重要事項の告知も、AIが勝手に情報を省略したり解釈を加えたりすることが許されない領域です。これらのNG領域については、AIに自由な発想を許さず、決められた定型文のみを出力させるか、あるいは即座に有人オペレーターへ転送するフローを設計することが不可欠です。
ハルシネーション対策の全体像「3層ガードレール」モデル
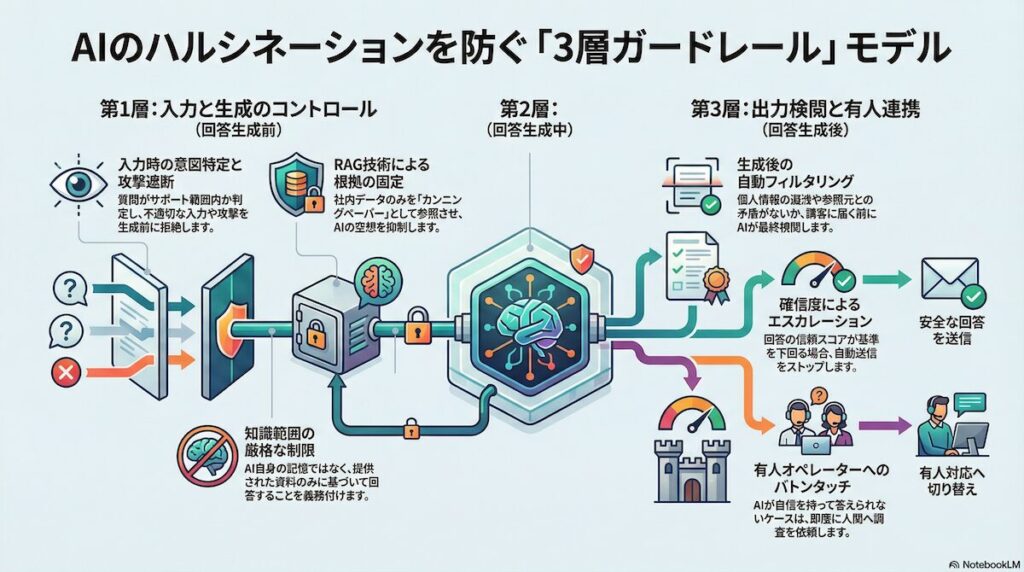
ハルシネーションのリスクを技術的に封じ込めるためには、単一の対策ではなく、AIの入出力プロセスの前・中・後に三つの検問を設ける「3層ガードレール」モデルの導入が有効です。各段階でリスクをフィルタリングし、最終的に顧客へ届く回答の精度を極限まで高めることが可能になります。
第1層:回答生成前(入力・意図・前提の整備)
最初の層では、顧客からの入力をAIに渡す前に精査し、AIの行動範囲を厳格に定義します。まず意図特定エンジンによって、質問が自社のサポート範囲内にあるかを確認し、政治的、倫理的、あるいは誹謗中傷にあたるような不適切な入力であれば、AIに考えさせる間を与えず即座に拒絶回答を出力します。
また、システムプロンプトの設計において、AIのアイデンティティを固定し、参照データ以外の知識を使用することを厳格に禁じる指示を与えます。さらに、ユーザーがAIを騙して制限を解除させようとするプロンプトインジェクション攻撃を遮断するためのフィルタを設けることも、この第1層の重要な役割です。
第2層:回答生成中(根拠ベースに縛る)
第二の層は、AIが回答をひねり出している最中に、その思考を現実のデータに繋ぎ止める役割を果たします。ここで活用されるのが、検索拡張生成と呼ばれるRAG技術です。
AIが自らの記憶のみで答えるのではなく、質問に関連する社内の最新マニュアルやFAQデータをリアルタイムで検索し、そのテキストを「カンニングペーパー」としてプロンプトに注入します。AIに対しては、あくまでこの提供された資料のみを要約・整形して回答することを義務付け、資料に答えがない場合には「わかりません」と潔く認めさせるロジックを組み込みます。これにより、根拠のない空想に基づく生成を物理的に抑制することができます。
第3層:回答生成後(検査・抑止・エスカレーション)
最後の層は、AIが生成した直後の回答案を、顧客の目に触れる前に自動で検閲する機能です。生成された文章の中に、学習データから漏れ出した他人の個人情報や不適切な表現が含まれていないかを確認します。
また、生成された回答が、参照元のマニュアルと内容的に矛盾していないか、あるいは論理的に不整合がないかを別のAIモデルを用いてスコアリングし、確信度が一定の基準を下回る場合には、自動送信をストップします。この段階で、AIは「自分では自信を持って答えられない」と判断し、人間である有人オペレーターに対して、対話の履歴とともにスムーズにエスカレーションを行うトリガーを引く設計が求められます。
技術的な対策のポイント
3層のガードレールを支えるためには、背後にある技術スタックの細かなチューニングが不可欠です。特にRAGの設計やプロンプトの工夫は、ハルシネーション抑制の成果を大きく左右する要因となります。
RAG設計のポイント
RAGを効果的に機能させるためには、検索の精度そのものを高める必要があります。単純なキーワード検索だけでなく、単語の意味の近さを数値化して検索するベクトル検索を組み合わせたハイブリッド検索を導入することで、口語体での曖昧な質問に対しても適切なマニュアルの箇所を特定できるようになります。
また、マニュアルデータをAIに読み込ませる際の分割単位、いわゆるチャンクサイズの最適化も重要です。チャンクが大きすぎると無関係なノイズが含まれ、小さすぎると文脈が断片化して正しい理解を妨げます。さらに、参照した資料のページ番号やURLなどの出典を回答文の中に明示させる機能を持たせることで、ユーザー自身が情報の正確性を確認できる透明性を確保することが推奨されます。
参考記事:RAGのチャンクサイズと検索手法(Vector Index / Summary Index)について考察してみた。Llama Index, LLM
プロンプト設計のポイント
AIへの指示出しであるプロンプトエンジニアリングにおいては、単に「答えてください」とするのではなく、回答に至るまでのステップを明示する手法が効果的です。
まず質問の意味を解釈し、次に資料から該当箇所を抜き出し、最後に回答案と資料の内容に相違がないかを自問自答させるという「思考の連鎖」をプロンプトに組み込みます。
加えて、少数の正解例をプロンプトに含めることで、望ましい回答のトーンや情報の網羅性をAIに学習させることも有効です。
また、不確実な場合の逃げ道として、「この質問には私の持つデータではお答えできません」という標準的な拒絶フレーズを学習させておくことで、無理な推測による生成を防ぎます。
AIモデルのポイント
使用するAIモデルの選択においても戦略が必要です。すべての用途に大規模で高コストな汎用モデルを使うのではなく、特定の業務に特化して学習された小規模言語モデル、いわゆるSLMを活用することで、不要な外部知識によるハルシネーションを構造的に減らすことができます。
また、クラウド型のAIサービスを利用する際には、入力したデータがモデルの再学習に利用されないことを保証する設定を徹底し、企業秘密や顧客情報が意図せず流出するリスクを遮断します。技術的な運用面では、ハルシネーションが発生した際のログを詳細に記録し、どの質問に対してどのガードレールが機能したか、あるいは機能しなかったかを可視化するダッシュボードを整備しておくことが、継続的な改善には欠かせません。
運用における対策のポイント
技術が防壁を作る一方で、それを適切に運用し、AIの限界を人間がカバーする仕組みを整えることが、コンタクトセンターにおける真の信頼性を担保します。AIと人間の協調、そしてそれを支える組織体制の構築が重要になります。
有人エスカレーション設計
AIによる自動化率を高めることばかりを優先すると、顧客を「袋小路」に追い込んでしまうリスクがあります。ハルシネーションの兆候があった際や、顧客が不満を示した際には、有人オペレーターに切り替わる導線を設計しておく必要があります。
オペレーターにエスカレーションする時は、単に繋ぐだけでなく、AIがそれまでどのようなやり取りをしていたのかという文脈を、オペレーターに連携する仕組みが求められます。人間が介入する際には、AIが提示した誤情報を前提として会話を始めるのではなく、フラットな状態で正しい情報を提示し直すためのオペレーション手順を確立しておくことが、信頼回復の鍵となります。
監視・評価・改善
AIの回答精度を維持するためには、人間による品質管理のプロセスを再定義しなければなりません。従来のモニタリング手法を応用し、AIが生成した回答のサンプルを定期的に抽出し、情報の正確性や根拠資料との一致度を専門の評価者がチェックします。
この際、ハルシネーションの発生率をKPIとして設定し、その推移を追いかけます。現場のオペレーターからのフィードバックも重要であり、AIが提示した回答案に誤りを発見した際、開発チームに報告できる仕組みを導入することで、迅速なデータの修正やプロンプトの調整が可能になります。AIによる自己評価指標と、人間による多角的な評価を組み合わせることで、精度の劣化を早期に検知できる体制を整えます。
ガバナンス(社内ルール)
AI導入を安全に進めるためには、法務や情報システム部門と連携した強固なガバナンスが欠かせません。
日本ディープラーニング協会などが提供するガイドラインを参考に、AIの利用範囲や責任の所在を明確にした社内規定を策定します。特に顧客とのやり取りをAIが行う場合、それがAIによる回答であることを明確に表示する義務や、提供される情報の法的効力に関する免責事項の提示方法などをルール化します。
また、AIが参照するマニュアルやFAQデータの管理責任を明確にし、情報の更新が遅れることで発生する「正解データそのものの誤り」を防ぐためのデータマネジメント体制を確立することも、広義のハルシネーション対策として極めて重要です。
対策事例
ここでは、ハルシネーションリスクに正面から向き合い、独自の工夫で安全なAI活用を実現している先進企業の事例を紹介します。
事例1:LINEヤフーコミュニケーションズ
大手IT企業グループのLINEヤフーコミュニケーションズでは、カスタマーサポート部門に生成AIを導入する際に厳格なセキュリティ対策と段階的な運用導入を実施しました。
具体的には、以下の4つの点を重視しています。
- 信頼性の高い生成AIの選定と契約締結(モデル選定)
- プロンプト設計によるリスク制御(不適切な回答をしにくい指示の工夫)
- セキュアなインフラ環境の構築(クラウド環境の選択・アクセス制限)
- 従業員への教育と利用ルール徹底
特に自社データをAIの学習に使わせない設計やゼロリテンション(会話データを保持しない)を条件にAI基盤を選定し、さらにプロンプトで出力内容を細かく制御して二重のセーフティネットを敷いています。
例えば、ユーザーが個人情報を入力した場合に自動検知して回答に反映させないなど、個人情報や機密情報を誤って出力しない工夫を実現しています。これらの対策により、リスクを抑えつつ現場への生成AI活用を進めている事例です。
参照:月刊コールセンタージャパン 2025年7月号 <特集>より
事例2:KDDI(auサポート)
通信大手のKDDIは、2025年11月にチャットサポート向けの高精度AIエージェントを開発したと発表しました。
このAIエージェントでは、KDDI総合研究所が世界初の特許取得をした「ハルシネーション抑制技術」を活用している点が特徴です。具体的には、過去の適切なオペレーター応対事例を複数参照し、それをもとに会話の流れを構造化します。さらに不足している情報があれば自律的に社内ナレッジなどから収集・ファクトチェックを行った上で回答文を生成する仕組みです。AIが勝手な推測で回答を作ることを防ぎ、回答精度約90%を実現したとされています。KDDIではこの技術を「auチャットサポート窓口」におけるオペレーター支援に活用し始めており、現場での有効性が注目されています。
事例3:大和証券
大手証券会社の大和証券では、コンタクトセンターに音声対話型のボイスボット「AIオペレーター」を構築し、FAQデータやマーケット情報をもとに自動応答させる実証に取り組みました。
金融業界ならではの厳格なコンプライアンス要件がある中で生成AIを活用するため、「誤回答」「情報漏洩」「不適切応対」といったリスクをいかに制御するかが最大の課題で、対策として、Azure OpenAIの標準フィルタリング機能に加え、プロンプトによる出力制御を組み合わせた“二重のガードレール”を設定しています。
また、全てのAI応答を自動監視する仕組みを導入し、AIがフラグを立てた回答は専門の担当者が目視でチェックする二段構えの運用体制を敷いています。例えば、不適切な内容や誤りの可能性がある応答は人間がレビューして訂正・介入できるため、重大な誤案内の発生を防いでいます。
参照:月刊コールセンタージャパン 2025年7月号 <特集>より
失敗しないロードマップ
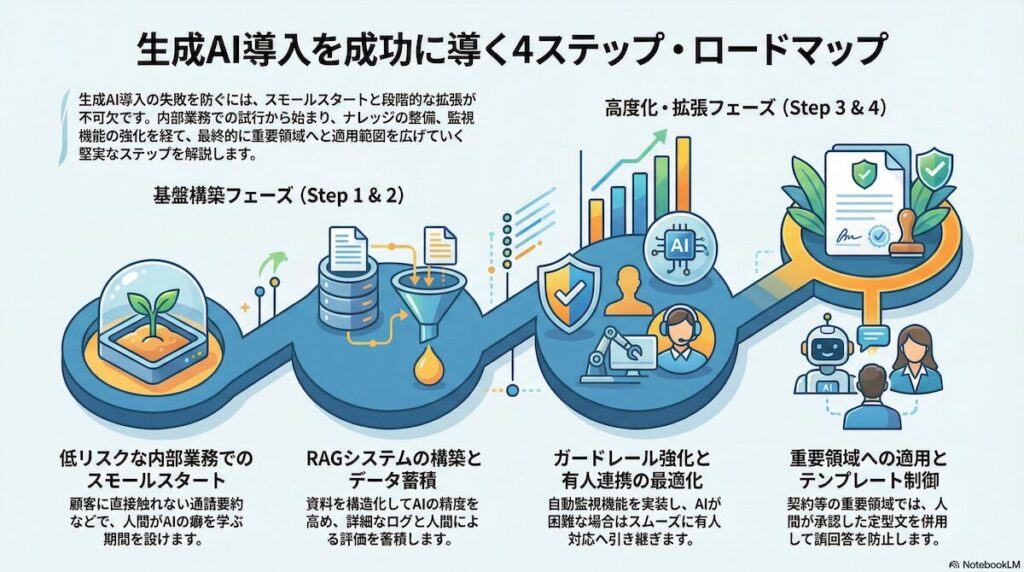
生成AIの導入を成功させ、ハルシネーションの脅威から身を守るためには、スモールスタートと段階的な拡張という堅実なステップを踏むことが推奨されます。
Step 1:限定ユースケース(低リスク)で開始
まずは、顧客に直接回答が届かない内部業務からAI活用を開始します。
例えば、オペレーターが応対した通話の要約や、社内マニュアルの検索支援などが最適です。この段階では、AIの出力はあくまで「下書き」として人間が確認・修正することを前提とします。現場のオペレーターがAIの癖やハルシネーションの発生パターンを肌感覚で理解し、リスクリテラシーを高めるための学習期間を確保することができます。
Step 2:ナレッジ整備+RAG+監査ログ
次に、AIの回答精度を高めるための基盤を固めます。
散在している社内のPDF資料やFAQをAIが理解しやすい形式に構造化して整理し、本格的なRAGシステムを構築します。この際、AIとのすべてのやり取りを詳細なログとして保存し、後からハルシネーションが発生した際の原因追跡ができる体制を整えます。同時に、AIの回答に対するフィードバックボタンをオペレーター画面に設置し、人間による評価データを蓄積し始めます。
Step 3:ガードレール強化+エスカレーション最適化
システムが安定してきたら、いよいよ入出力の監視機能を強化します。
先に述べた「3層ガードレール」を実装し、不適切な発言のフィルタリングや矛盾検知の自動化を進めます。また、AIが自身の回答に自信が持てない場合に、適切なタイミングで有人オペレーターにバトンタッチするエスカレーションの導線を磨き上げ、顧客がAIの誤回答によるストレスを感じないようなスムーズな体験を設計します。
Step 4:重要領域へ拡張(テンプレ+例外処理)
最終ステップとして、契約や金銭に関わるような重要度の高い領域へ適用範囲を広げます。
ただし、この領域ではAIに完全に自由に喋らせるのではなく、重要な情報はあらかじめ人間が承認したテンプレートを引用させるなど、例外的な制御を組み合わせます。これまでのステップで蓄積された評価データと改善のサイクルが機能していれば、万が一のハルシネーションが発生しても、被害を最小限に抑えつつ、AIの恩恵を最大化できるようになります。
ハルシネーションに関するまとめ
本記事では、コンタクトセンターにおける「ハルシネーション対策」について解説しました。
ハルシネーション対策の核となるのは、AIを「根拠あるデータ」に基づいて回答させる仕組み、AIの限界を認めて速やかに「人に戻す」設計、そして常にモニタリングを続けながら「改善を回す」ことの三点に集約されます。
技術的なガードレールは日進月歩で進化していますが、最終的にサービスを支えるのは、AIの特性を正しく理解し、適切に使いこなそうとする人間の知恵と体制です。AIを単なる効率化の道具としてではなく、人間の能力を拡張し、共に顧客の課題を解決するパートナーとして位置づけること。
そのために必要な堅牢な設計こそが、次世代のコンタクトセンターが顧客の信頼を勝ち取るための唯一の道となるでしょう。
業務効率化や人手不足のお悩み、AI×BPOで解決しませんか?
「業務の生産性を上げたい」「少人数でも高品質な対応を実現したい」そんなご要望はありませんか?
ウィルオブ・ワークでは、BPOサービスを通じた業務支援に加え、AIと人のハイブリッド型BPO(AI-BPO)の導入支援も行っています。
お客様の業務内容や体制に応じて、最適な改善策をご提案いたします。
Writer編集者情報
-

コネナビ編集部 上原 美由紀
採用支援・求人広告会社にて、アルバイト・パートや中途採用を中心に、約3年間にわたり企業の採用支援業務に従事。
2019年9月より株式会社ウィルオブ・ワークに入社。コールセンター・オフィスワークに特化した人材サービスの事業部でキャリアアドバイザーを担当。現場で培った知見をもとに、コンタクトセンター領域はもちろん、採用・人材分野に関する実践的かつリアルな情報発信を心がけている。
趣味:音楽、ゲーム、ディズニー、お酒
特技:タスク管理







